Exploring ML Tools - Transcribe
Posted on Fri 29 May 2020 in blogs
Audio is part of our life which exists in many forms like, voice messages, podcasts, songs, lectures, recorded conversations etc. These files are really hard to process by computer and so it just stays in magnetic disk or expensive disk and never actually used proactively unless its needed. However, machines have become very intelligent in process texts. And thus, so we can convert audio to text and put machine to work for getting insight.
Introduction
There have pretty good research in speech-to-text conversion with model like Hidden Markow Models(HMM), Dynamic Time Warping and many neural networks. AWS have provide fully managed service called AWS Transcribe which can be used to transcribe audio, video files and also transcribe medical files.
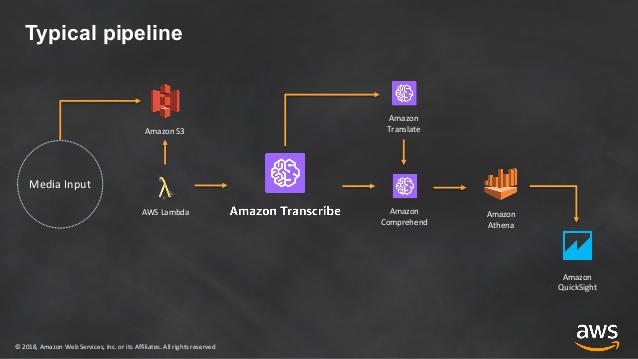
How it Works?
- Input can be provided to AWS transcribe in following ways:
- Files in audio format using StartTranscriptionJob.
- Bi-directional HTTP/2 stream using StartStreamTranscription.
- Websocket protocol.
- It returns transcription with highest level of confidence, however, you can additional transcribes by setting ShowAlternatives to true and MaxAlternatives to your required number.
- For speaker identification(diarization), the result is best when the number of speaker set is same as actual number of speakers in the clip.
- For Channel Identification, it split the file into multiple audio files and provide multiple transcribe along with combined file. The overlap audios are transcribe based on audio start time. This can be done by setting ChannelIdentification flag.
- You can provide custom vocabularies which can be of upto 50 Kb size. The data can be in list format or table format.
- Automatically redacts sensitive PII data which includes Bank Account Number, Credit Card details, Phone numbers, etc. It will replace it with [PII] tag. We can set RedactionType flag to PII under ContentRedaction.
- You can also enable Queuing for the transcribing as there are limited slots available for job and when queuing is enabled then it will process as soon as slots are available in FIFO order.
Features
- Support transcribing of many languages. Detail list can be found here.
- Identifies speakers in the audio.
- Transcribe separate channels like in call centre recording, it can give two separate files, one for representative and other of customer.
- Streaming audio transcribing.
- Custom Vocabulary
Usecase
- Generate captioning of video recording.
- Generating subtitles of the video.
- Call centre recording analysis.
Usage
The AWS transcribe can be used via: * AWS cli * AWS Console * AWS SDK
Input
-
Accepted input format is FLAC, MP3, MP4, or WAV file format. Should be less than 4 hours in length or 2 GB in size. Latest updated limits can be found here.
-
Transcribing Numbers:
- There are set of rules for transcribing the numbers which can be found here.
- In few languages, the numbers are transcribed into digits. In others, the numbers are converted into word.
Process
Following steps will walk through transcribing steps via python SDK.
- Initialize aws transcribe client
import boto3
transcribe_client = boto3.client('transcribe', region_name='eu-west-1')
- Start Transcribing job
short_job_uri = "https://s3.eu-west-1.amazonaws.com/exploring-ml-tools/aws-transcribe/assets/VodaFoneCallCenter.mp3"
# Start Transcribing job
job_name = "TEST_JOB_With_VodaFone"
trascribe_response = transcribe_client.start_transcription_job(
TranscriptionJobName=job_name,
Media={'MediaFileUri': short_job_uri},
MediaFormat='mp3',
LanguageCode='en-IN',
Settings={
'ShowAlternatives': True,
'MaxAlternatives': 6
}
)
- Get Transcribing job details
import time
# Get Transcribing job
while True:
status = transcribe_client.get_transcription_job(TranscriptionJobName=job_name)
if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']:
break
print("Not ready yet...")
time.sleep(5)
print(status)
- Downloading transcript
if status['TranscriptionJob']['TranscriptionJobStatus'] == 'COMPLETED':
uri = status['TranscriptionJob']['Transcript']['TranscriptFileUri']
response = requests.get(uri)
if response.status_code == 200:
json_data = json.loads(response.text)
json_data['results']['transcripts']
# Output >>>[{'transcript': 'his taste for a phone call centre.'}]
If you dont specify output bucket then transcripts will be deleted after expiration of job that is in 90 days.
Output
The output files can be stored in your output bucket if specified in job or by default transcribing job stores the data up to 90 days. The output will contain alternatives as well which show other output with various confidence level.
Also, if we have enabled redaction then the redacted file will replace the PII value with [PII] tag.
Cleanup
- Deleting Transcribing job
# Delete Transcribing job
response = transcribe_client.delete_transcription_job(
TranscriptionJobName='TEST_JOB'
)
Transcribing job expires in 90 days.
Findings
- It takes approximately 1.5 minutes to transcribe 3-second-long audio and 3.5 mins to transcribe 27 mins audio.
- Good transcribing of UK and US English.
- When transcribing english, the only language supported to transcribe using redaction enabled was en-US, for other you will need to enable it on your AWS account.
Pricing
- No upfront cost
- Free tier:
- 60 mins/month for 12 months
- On demand:
- Detailed list can be found here