Connect Jupyter Notebook to AWS Glue Endpoint
If I am not wrong, then almost everyone in data engineering industry have heard of Apache Spark and if not (highly unlikely) then you are just one google search away for ample number resources. This post will revolve around Spark, AWS Glue, notebook and binding these tools for optimal results.
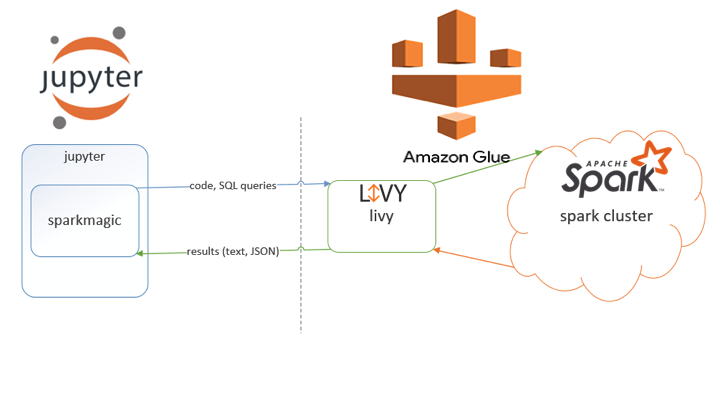
Introduction
As Spark has been here for more than 10 years and industry have recognized its potential, thus many companies have orchestrated this framework and started providing it as service. Amazon is of it with offerings like AWS EMR and AWS Glue (Fully managed). AWS has done most of the heavy lifting for us and provided fully managed spark service which can be scaled to more than TB of memory. It also provides Glue Endpoint, which is long running spark cluster and you can connect to its REPL or launch a zeppelin or jupyter notebook deployed in cloud.
However, as a developer wants to retain all the notebook he/she creates for future(I think it make sense to save anyway, losing something is hurtful), one has to implement some custom logic like saving in S3 or Github or downloading locally(not a good decision at all). It makes sense if we can just leverage our locally installed jupyter and connect to spark, we dont need to change much and plus more importantly it saves $$ (For running notebook in cloud).
Set up
We will need a:
- Glue Endpoint
- Jupyter Notebook
- sparkmagic
pip install jupyter
pip install sparkmagic
python -m jupyter nbextension enable --py --sys-prefix widgetsnbextension
Install spark kernels
Get the spark magic location and ‘cd’ to that directory
# Get the sparkmagic location
pip show sparkmagic
# The location will be different for you
cd ~/.local/share/virtualenvs/jupyter_to_glue-5i9d0kFW/lib/python3.6/site-packages
# Install spark kernel for scala spark
jupyter-kernelspec install sparkmagic/kernels/sparkkernel
# Install pyspark kernel for python spark
jupyter-kernelspec install sparkmagic/kernels/pysparkkernel
Copy the config.json into ~/.sparkmagic/config.json
Connection to AWS Glue Endpoint
I believe you would have launched glue endpoint with your public ssh key, it will take nearly 10 mins for it be available to connect.
After provisioning, get the details to connect to Glue Endpoint, for example something like
`ssh -i <private-key.pem> -vnNT -L :9007:169.254.76.1:9007 glue@ec2–3–70–179–133.compute-1.amazonaws.com`
However, we need to change the SSH tunnelling port to get tunnel the Livy server port (8998) which is a rest client to connect to spark cluster. And thus the final tunnelling looks like
ssh -i ~/.ssh/id_rsa -vnNT -L 8998:169.254.76.1:8998 glue@ec2–3–70–179–133.compute-1.amazonaws.com
You can verify that livy server UI is available at localhost:8998
Leave the shell open for connection to be maintained or you can detach it using nohup or any tool of your choice.
Launching Jupyter Server
Now we launch jupyter server using command: jupyter notebook
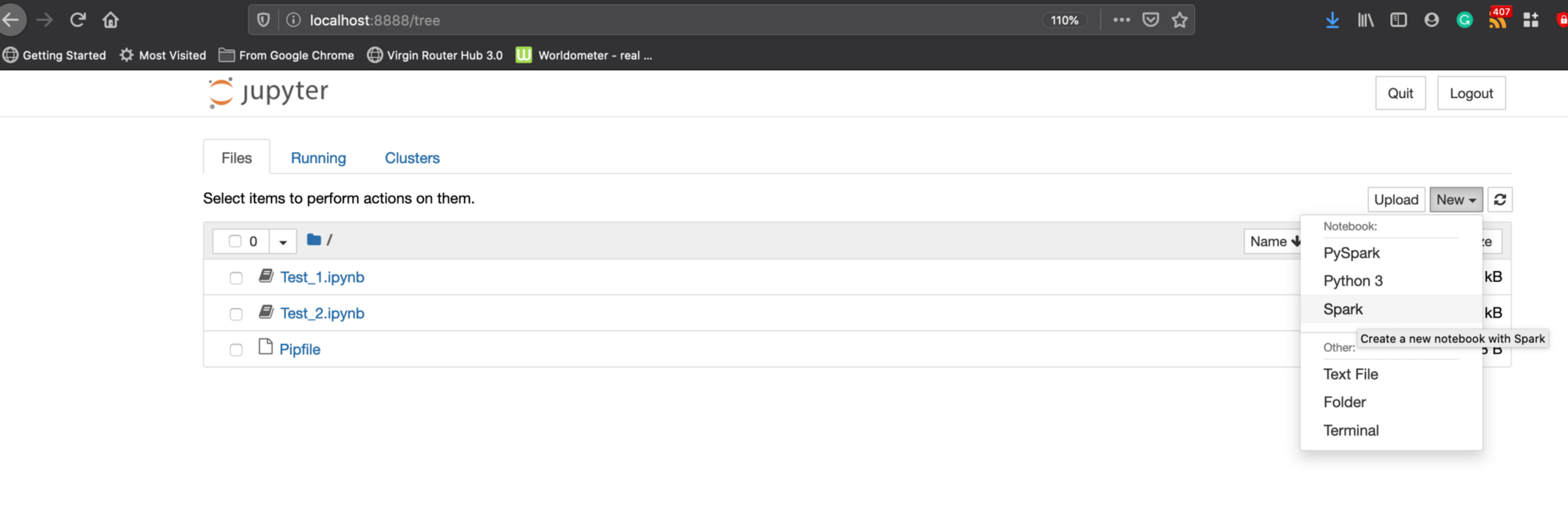
As you can see now you can find two new kernels PySpark (for python) and Spark (for scala).
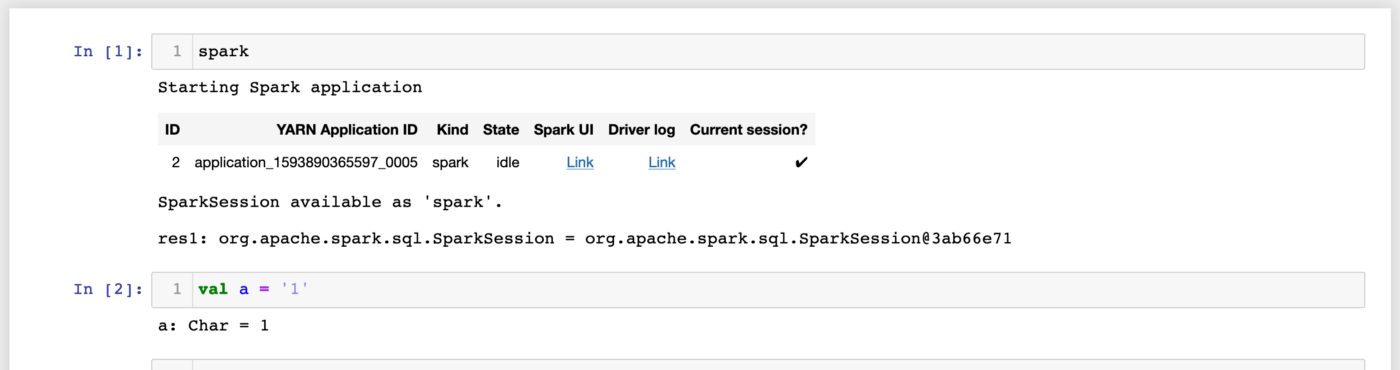
As you can see we can access Glue Spark and also save the notebook when the endpoint is stopped.
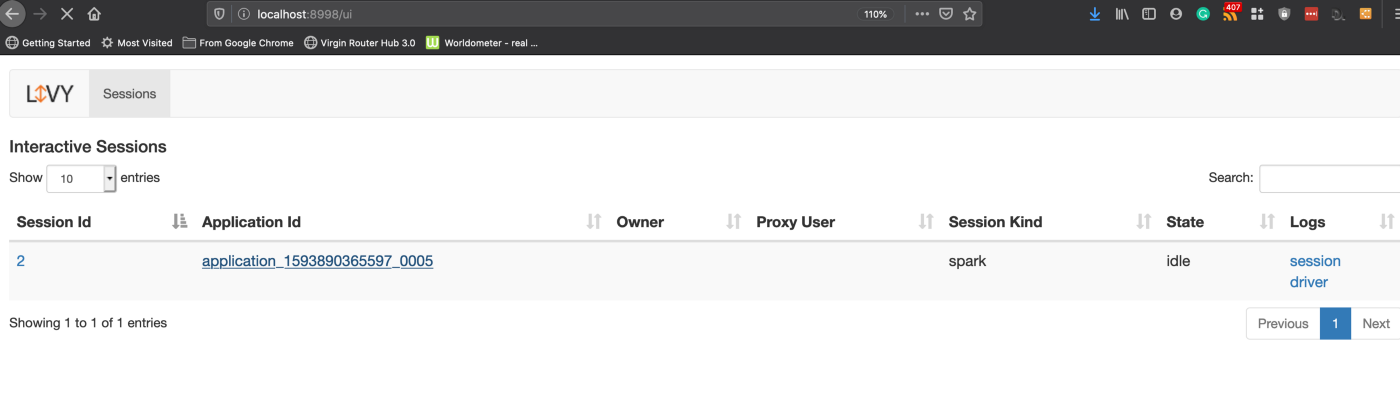
Also, you can access livy server UI to monitor multiple sessions by going to:
Benefits
- No need to keep endpoint running as all codes are saved to your notebook.
- No need to extract data out of S3 to your notebook to perform feature engineering.
- Can share the spark cluster among the team, resulting in cost saving.
- Can perform ad hoc logic of TB’s of data.
- Endpoint can scale to 50 DPU which is approximately (16 x 50 = 800 GB memory and 4 x 50 = 200 cores) 100 executors.
Pricing
Glue is priced per DPU which stands for Data Processing Unit
$0.44/Hour/DPU, billed per second, with a 10-minute minimum.
Bibliography
- https://blog.chezo.uno/livy-jupyter-notebook-sparkmagic-powerful-easy-notebook-for-data-scientist-a8b72345ea2d
P.S. Please delete the endpoint after your development or be ready for big fat bill from AWS